基于传感器数据的行为识别

杨 强 郑文琛 胡 昊香港科技大学
引言
随着传感器制造技术的发展、制造成本的进一步降低,传感器应用已经变得越来越普遍。传感器技术的成熟使得利用传感器收集环境数据以获取环境和用户信息变得切实可行,并极大地推动了医疗辅助、环境监测、煤矿安全等多个相关领域的发展。
此外,对基于传感器的行为识别的研究对整个普适计算领域也有着很重要的影响。移动设备、掌上电脑的出现使得随时随地进行“计算”成为可能,而且传感器数据的普及又使得在这些移动设备上进行相关的行为识别成为可能。
这里,要特别强调,基于传感器的数据挖掘和基于传感器网络的数据挖掘有所不同。前者是以任何通过传感器所采集的数据为基础,建立用户的行为模型。这些传感器包括传感器网络,但也可以包括非网络的传感器,如GPS和WiFi等;后者则偏重于研究在有限的带宽、能量等因素的情况下,各种数据传输的问题。相比之下,在此提到的对于传感器的要求,只是在数据获取的层面。而未来的研究方向,也可以包括如何利用各种传感器网络进行行为识别。
与其他数据挖掘的技术相比,基于传感器的数据挖掘有其特殊的几个层面,分别为传感器层面、数据层面和识别目标层面。
首先是传感器层面。图1展示了几种常见的传感器。图1a展示了三种常见的GPS传感器,它们可以用于获取卫星信号以识别用户的位置及预测用户的行为[17]。图1b显示的是一种常用于构建无线传感器网络的MICA2传感器,该传感器可应用于在无线传感器网络中的定位等[2]。图1c是英特尔公司研究院设计的一种腕带型射频识别传感器,可以用于读取贴于物件上的射频识别标签,进而记录用户对物件的使用情况[13]。图1d是美国麻省理工学院设计的一种加速计传感器,它可以检测到佩戴用户在运动时在三个维度上的加速度,通过模式分析即可推断用户的动作(如跑步等)[14]。

除了图1所展示的四类传感器,还有很多其他传感器可被用来获取丰富的环境和用户的周边信息。例如,红外线传感器可以用于构建目标物体表面温度的热像图,温湿度传感器可以用于监测环境温度和湿度的变化等。
仔细分析,可以发现这些传感器大体分为两类。第一类是小范围传感器,比如MICA和射频识别等(图1b、c、d)。这类传感器的特点是非常精确,信息量大。但传感范围小,价格昂贵。所以,至少在今天,仍不能为大众所使用;第二种为大范围传感器,如全球定位系统(Global Positioning System,GPS)(图1a)和无线保真(WiFi)。这类传感器的特点是范围极大,大部分地方都可以接受到信号。但信号的信息量非常有限,如GPS的信号只告知位置信息,WiFi的信号还带有很多的噪声。其他更加有用的信息则需要通过设计智能的,能够处理不确定数据的算法来挖掘获得。
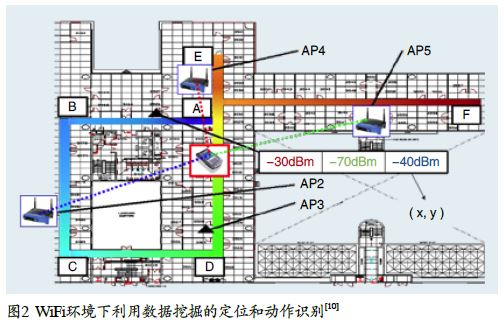
其次是数据层面。当大量传感器的数据得到积累,可通过数据挖掘的方式来分析和获取传感器数据当中蕴含的用户行为模式,以完成对老人监护等任务。这些传感器各有不同,因此其输出数据也不同。例如,有些传感器如射频识别等可以输出二元数据(0或1),而WiFi产生的数据却是连续的。这些问题可以通过数据的共同化来解决。要达到这一目的,可以把传感器的数据产生过程分为传感器部分和探测器部分。传感器负责传播信号。这些信号被探测器收到后,形成一个向量。图2所示为一个在WiFi环境下的信号传播过程。当然,这个传感器-探测器的角色也可以互换。同时,这样收到的数据还可以是一个或多个时间序列。
由此可见,这样的时间系列的向量形式所表达的数据将会非常复杂,以至于能够挖掘得到的信息非常有限。在此前提下,若希望得到有用的信息,一般来说研究者都会希望数据密度足够大,并且加入的人工标注的信息足够多。例如,人工可以标注一部分的数据为老人吃药这一动作所产生的数据,而另一部分则为老人看电视的信息。往往人工标注的信息越多,所能挖掘到的信息就越多越有用。所以,围绕着数据标注的信息量以及数据稀疏程度的问题,可以把数据分为“稀疏、缺乏标注的数据”和“密集、有标注的数据”。而绝大多数的传感器数据都属于前者。
最后是区分动作识别的目标。这也可以分为两种,即用户位置信息获取和用户动作信息获取。位置信息对于理解一个用户的行为有着十分重要的地位。用户的位置轨迹信息不仅记录了用户在真实世界的活动,还在一定程度上反映出了用户的个人行为和兴趣喜好。例如,某个用户经常出现在学校,那么可以推断该用户很有可能是学生或老师;如果这个用户还经常去郊外游玩,则能推断出该用户可能很热衷于户外运动,等等。此外, 随着多个用户位置轨迹信息的积累,还可以从中发现一些有意义的模式,并利用它们来提供许多有用的基于地理位置的服务,包括基于位置和轨迹信息的交通模式识别、广告、搜索、社交网络等。例如,廖(Liao,音译)等人提出根据用户移动的轨迹速度及位置来估计用户是否在步行或者开车,并推断用户是否在工作或者正外出访友[18]。郑(Zheng,音译)等人提出根据众多用户的GPS轨迹数据来发掘一个城市的兴趣点和旅行专家,进而提供旅游热点区域和热门路线的推荐[1,19]。Foursquare.com等基于地理位置信息的社交网站的兴起则为手机用户搭建了一个互联网社交平台,极大地推动了基于地理位置的广告投放模式的发展。
现通过一个利用WiFi进行室内定位的例子来说明基于数据挖掘学习定位的工作原理。如图2所示,用户通过手持无线设备在一个WiFi环境内移动。在不同的地点,用户可以检测到多个无线接入点(Access Points,APs)。基于用户与多个无线接入点的距离远近,用户可以从各个无线接入点测量得到不同的信号强度,如S=(-30dBm,-50dBm, -70dBm)。与此同时,该信号还对应于某个特定的位置。如果把定位问题看成是一个机器学习的分类(Classification)问题,那么相当于是把一个环境建模成一个有限的位置空间L={l1,…,ln},然后对某个信号强度数据S进行分类推测其类别(即L的某个取值)。如果考虑位置坐标为连续值,那么也可以把定位问题看成是一个机器学习的回归(Regression)问题。然而,这类定位方法也有其不足之处,例如,为了建立定位模型通常需要收集很多标注数据(Labeled Data)。为此,一些研究人员还提出利用半监督学习(Semi-SupervisedLearning)甚至是非监督学习(Unsupervised Learning)来减少对标注数据的需求[2~3]。
对于基于数据挖掘的定位方法,一个重要的假设是信号的数据分布(Data Distribution)不会改变,但是这个假设在实际的动态环境中经常不成立,这就使得训练好的定位模型容易在信号分布改变的时候失效。最近的研究是将这个问题看成是迁移学习(Transfer Learning)的一个应用,即如何利用已有的信号标注数据来最小化重新收集到的标注数据,以更新和保证定位系统的性能。针对WiFi的信号强度可能随着时间、设备以及楼层环境的变化发生变化的情况,提出多个迁移学习的算法来快速更新定位系统[4~6]。
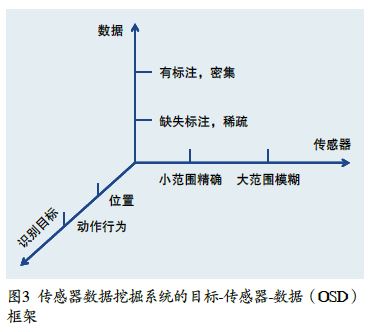
综上所述,基于传感器的数据挖掘可通过分类,建立一个对于传感器系统的分类框架,如图3所示。根据传感器种类、数据形式和识别目标,可以清楚地看到每一项前人的工作在这个坐标系里所处的位置。为一个用户定位仅仅能解决我们关心的某些问题,但不能回答诸如“老人下面的行动目标将是哪些?”这样更高一层的问题。因为,要回答这些问题必须对用户高层的行为及目标(Goals)有一定的了解。这也是现在研究比较薄弱的一个环节。图3所给出的分类系统是根据识别目标(Objectives),传感器类型(Sensor Types)和数据类型(Data Types)所进行的分类模型,因此,可以称之为OSD框架。这里将着重讨论在OSD框架下,我们的研究小组在传感器数据挖掘这方面的几项工作:在标注数据缺乏的条件下基于多人数据的行为识别以及稀疏行为数据环境下的动作识别问题。
基于传感器的动作行为识别的基本原理
传感器可以用来帮助对用户动作行为的识别。
通过在日常物品上放置射频识别传感器,就能识别用户对物品的使用情况,从而判断用户的动作。例如,当用户在泡咖啡的时候,可能因为需要使用咖啡机和储存咖啡的壁橱,触发了咖啡机上和壁橱上的射频识别传感器。当行为识别系统捕捉到这些传感器信号后,就可以由此判断用户正在泡咖啡。另外,也可以通过利用传感器来获取用户的位置信息从而推断用户的行为。例如,根据用户在办公室环境中的移动,就可能判断该用户是否正要去开会或者只是去复印文件;在室外环境中,根据用户的位置还能判断其是在办公室工作还是在户外运动。所有这些用户动作信息的获取为理解用户行为提供了很大的帮助,并催生了一系列具有广阔前景的应用,比如基于行为识别的医疗健康监测[7]和基于异常行为检测的安全控制[8],等等。
早期的行为识别方法是基于逻辑的。其工作原理是将(有限的)环境状态和目标动作(有限的)被描述成逻辑表达式,进而通过逻辑推理的方式判断目标的行为[9]。后来,随着传感器被普遍应用于检测环境状态,基于数据挖掘的行为识别方法因其能够较好地解决数据的不确定性而开始受到越来越多的关注。以下将从一个基于WiFi数据进行室内行为识别的例子出发介绍如何利用数据挖掘来实现行为识别,并讨论如何把一些不同的数据特征纳入考量并加以建模以获取较好的行为识别性能。
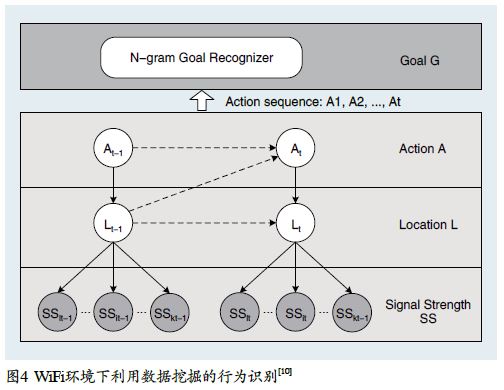
文献[10]给出了一个基于WiFi传感器数据进行室内行为识别的动态贝叶斯网络(Dynamic BayesNetwork)模型(如图4所示)。在该模型中,带阴影的节点SS表示从无线接入点收集得到的WiFi信号数据,它们是观察数据(Observations);其他非阴影的节点比如L、A和G都是隐变量(HiddenVariables),其中L表示用户的位置比如“在走廊的一端”或者“在某个房间的门口”,A表示用户的动作比如“进入某个房间”或者“经过某条走廊”,G表示用户的目标比如“去会议室听报告”或者“去复印室打印文件”。我们的目标是通过这些观察数据(即信号数据SS)来推断出所有的隐变量(即用户的位置变量L、动作变量A和目标变量G)。考虑到用户移动的时序性,该模型首先会根据用户收集到的WiFi传感器信号数据SSt及其在上一时刻的位置Lt-1,来判断该用户当前所在的位置Lt。例如,根据当前的WiFi信号推断出当前的可能位置有2个,一个靠近房间R,另一个远离房间R,但是考虑到上一时刻用户的位置是在房间R附近,就会估计当前时刻的位置应该是靠近房间R的那个位置。基于用户位置的变化,该模型还能推断出当前用户所执行的动作A t。例如,根据用户的位置变化,若发现用户正在不断靠近房间R,就能推断用户的动作为“进入房间R”的概率应该高于其他动作。在推测得到用户一系列的动作A1~At之后,可以预测该用户的目标行为G是使得如下条件概率最大的那个值:

比如用户先“经过某条走廊”(即At-1 =“经过走廊”),然后“进入房间R”(即At =“进入房间R”),而房间R通常用来打印文件,那么就能预测用户整个动作的目标G是“打印文件”,因为对应的概率P(A1:t | G)会比较大[10]。
以上例子简单说明了如何从一系列传感器读数中挖掘出用户的位置和行为信息。其实,用户行为除了跟地点有关,还取决于时间,动作发生顺序等因素,比如用户工作的时间通常发生在工作日白天,而很多用户在下班之后是先去健身房锻炼然后再去购物最后才开车回家。这些数据特征都可以直接从传感器数据中抽取出来作为模型输入。另外,考虑到现实世界中,用户行为通常还具有并发性(如看电视跟吃零食可能同时发生)和交叉性(如在做晚餐的时候接到电话,电话之后再继续做晚餐) 的特点,所以在利用数据挖掘的时候把这类行为的约束性信息考虑到模型中来。例如利用Skip-Chain Conditional Random Field来模拟行为发生的交叉性的特征,并通过一个Goal Graph来表示行为的并发性约束[11]。
为什么行为动作的预测对于老人们的居家监测和护理会有帮助呢?首先,如果能够在居家环境下正确地预测老人们动作的目标,就可以及时地对老人们提供各种帮助。例如,如果老人们的目标是吃药打针,但是想不起来其中的某些步骤,计算机可以根据预测到的目标对老人提供及时的提醒。再则,一个动作模型概括了一个人的行为模式。如果那个人现在的行为偏离了这一模式,那么,很有可能有意外情况将会发生。对于一个老年人来说,早些发现这些异常的情况,会有利于防止意外的发生。
如果上述的概率模型是建立在室内环境下的WiFi网的基础上,则根据图3所示的OSD框架,这种模型可以归纳为<识别目标=“动作行为”,数据类型=“有标注,密集”,传感器=“大范围,模糊”>。
动作行为识别的稀疏数据问题及解决方案
通过传感器进行行为识别时,不但可以利用单人的数据,还能够利用多人的传感器数据来挖掘出一些群体性的行为特征信息。例如,当发现有很多用户去到同一个地方L就餐,就能推断这个地方的餐馆可能非常受欢迎,所以很多人选择去L就餐。
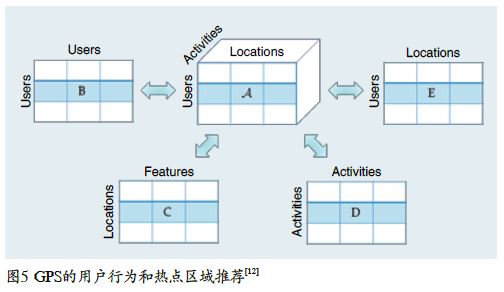
因此,当遇到一个用户也去相同的地方L,就能推断他可能是去就餐;另外,还能根据其他相似用户的行为,例如他的朋友除了喜欢去L就餐,还喜欢去另外一个地点Lb看电影,就能预测这个用户可能也会喜欢去Lb看电影。根据以上例子,可利用GPS数据来挖掘用户的行为,并以此进行用户行为和热点区域推荐[12]。其模型如图5所示,用户的位置轨迹及对应的行为数据被建模成一个三维的数据tensorA,其中tensor的每一项表示某个用户去某个地方做了某个行为的频度。例如,用户“张三”经常去中关村逛街购物,则在这个tensor中会有某一项“张三—中关村—逛街购物”,它的值等于“张三”去中关村逛街购物的次数。由于每个用户的数据有限,所以可以预见该tensor非常稀疏。例如,根据GPS,可以知道一个用户去了某个地方,但由于该用户没有提供任何标注数据,而无法知道他在那里做什么;又或者由于这个用户从来都没有去过某个地方,当想猜测他会不会想去这个地方做一些事情时,只能根据他的历史数据还有其他一些相似用户的行为数据来帮助推测。
为此,引入协同推荐(Collaborative Filtering,CF)的概念,来综合考虑多个用户的历史数据和其他一些可用的信息。在基于GPS的用户行为识别中,目标是想知道一个用户是否会对某个地方l做某件事情a感兴趣,例如,张三会不会对到中关村逛街购物感兴趣。首先需要看有哪些用户跟当前用户“张三”是相似的(通过用户相似度矩阵B),而他们是否会感兴趣去同样的地方做同样的事情(通过用户轨迹矩阵E及其tensor A)。例如,另外一个用户“李四”跟“张三”很相似,他们是朋友,经常一起出去玩。当发现“李四”很喜欢去中关村逛电子市场时,则可推测张三也许会对去中关村逛街买东西感兴趣。此外,还可判断某地方l是否会产生对应的行为a(通过位置特征矩阵C可知一个地方有多少家餐馆、银行和学校等)。我们可以猜测,“张三”可能会感兴趣去中关村逛街,但不大可能去那里做户外体育运动。最后,还可以利用各种行为之间的相关性来帮助做判断,例如吃饭跟逛街购物经常一起发生,但是体育锻炼就跟逛街很少一起发生,那么当知道有很多人都喜欢去中关村吃饭,就可认为“张三”去中关村逛街和吃饭的概率会很大。将以上所提到的所有信息综合起来,通过一个基于tensor分解的协同推荐模型,就能将每个用户的行为推断出来,并以此来对这些用户进行热门地点和行为活动的预测和推荐。当某个用户想知道能去哪里吃饭,这个模型就能根据多人的经验返回一个热门地点列表。以北京海淀区为例,返回的列表就可能是“中关村>五道口>……”。另外,去了某个地点都能做些什么事情,这个模型也能对应地推荐一系列热门的活动,以中关村为例,返回的列表就可能是“逛街购物>吃饭>电影>……”。
我们跟踪收集了164名用户在2.5年内所有的GPS数据,并以此进行了一系列的实验。根据实验结果发现,通过利用多人的历史数据和额外信息,与那些不利用这些信息的方法相比,能够将行为识别和热门地点区域推荐的性能分别提高22%和19%。
再以老人健康情况的监测问题为例。利用GPS以及行为推荐算法,至少可实现两个重要目标。第一,可以对老人的健康状况进行在线评估,以建立老人在室外的行为模型。如果在行动中的行为与他们以往的行为大有不同,可以推断老人是不是表现出某些疾病的特征。例如,老年痴呆症的早期症状就包括老人会突然忘记自己的行动目标和地点。这样就可以提前对老人及时地进行治疗和护理[8,17]。另外,可以通过与医院的合作,建立一个老人吃药的时间表,监护老人及时地吃药和接受治疗。美国密执根(Michigan)大学所做的Autominder系统[7]就是这样的一个系统。
同样,可以把以上的行为识别和推荐模型归纳到图3所示的OSD框架下,此模型可归结为<识别目标=“动作行为”,数据类型=“有部分标注、稀疏”,传感器=“大范围、精确”>。这里,传感器数据主要是GPS数据,而GPS数据可以给出精确的位置信息。但是,从位置信息延伸到行为信息,却要经过合理的概率模型来推断。
动作行为识别的标注缺乏问题及解决方案
通过对基于传感器的动作行为识别问题以及所提出的一些算法进行的简要分析,不难看出,在前面的描述中都隐性地给出了一个假设,即可以较为容易地获取带有标注的训练数据。这些训练数据通常是直接标注于相应的传感器数据上,以告诉用户当传感器接收到这样一组数据时,实际上在做什么。这些已标注的训练数据成为了算法的基石。
然而,一个无法忽视的问题是,随着传感器在各种设备中得到大规模的应用,所能收集到的传感器数据也就日益增多,而如何给不同的传感器数据进行手动的标注则成为一项冗繁的工作。
另一个需要考虑的因素是人类所能从事的活动种类繁杂多样且不可胜数。如果采用传统的监督学习的办法来构造一个能够对日常生活中的行为进行识别的分类器,就必须给这个算法提供包含了各种日常生活中行为的传感器数据,而这显然很难办到。因此,在上文中看上去完美无缺的体系在实际应用中有一个很致命的漏洞,即“标注缺乏问题”。换句话说就是,当行为识别系统需要去识别一套新的行为的时候,缺乏相应的训练数据来训练所需要的分类器。在现阶段,通常所设计的行为识别系统只能识别某一个特定的行为集合,如洗衣服、洗盘子、打扫卫生这一类。而如果这时又想识别一些其他行为,如拖地、扫地,那么是否有办法利用已有的标注数据呢?文献[16]提出了一种用于解决标注缺乏问题的方案。简单说,如果可以知道一些信息,例如“洗衣服”和“拖地”比“吃早饭”和“拖地”这一对活动的相似度要高一些,则可以得到如果现在需要识别“拖地”这个行为,则“洗衣服”的标注数据相对来说可能比“吃早饭”的标注数据用处要更大一些。文献[16]将此问题看作是迁移学习的一种应用。
基于上述思路,此问题的难点就变成了如何自动地学习两个行为之间的相似度。文献[16]提出了一种基于万维网(Web)搜索的算法来解决这个问题,算法描述如图6所示。
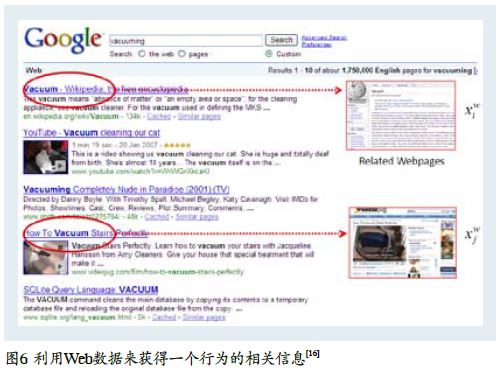
图7是从谷歌中的搜索“吸尘(Vacuuming)”这个活动所得出的网页。当搜索Vacuuming这个词的时候,一般来说在返回结果中排名比较靠前的网页都是和Vacuuming密切相关的,因此这些网页中应该包含很多和Vacuuming这个活动直接相关的词语。不论是名词(Vacuuming的主体或者是客体)或者是动词(如何做Vacuuming这个活动),为了使得处理更加简洁,首先只关注与行为相关的名词,这些名词中一般会包含这样几部分:第一是谁做这个行为,也就是行为的主体;第二是用什么工具来完成这个行为,第三是这个行为会作用在什么东西上,也就是行为的客体。
因此,如果两个活动在本质上比较类似,则很有可能在上述的三种名词中有重叠的部分。基于这样的观测和假设,所采用的计算两个行为A和B相似度的方法非常简单,首先将A作为查询送入搜索引擎中,得到了很多和行为A直接相关的网页,之后再将B作为查询送入搜索引擎中,同样可以得到很多和行为B直接相关的网页。截取出这两组网页集合中的名词,再计算这两个名词集合的相似度。之后,以这两个名词集合的相似度直接作为所计算出的行为A和行为B的相似度。
计算出相似度以后,可以将原有的标注在行为A上的训练数据迁移到行为B上。具体的说,如果行为A和行为B计算出来的相似度的值是0.9,则可认为,假如直接把标注为行为A的训练数据标注成行为B,这个事件的信度(confidence)是0.9。基于这样的假设,文献[16]采用了一个带权的支持向量机模型(Weighted Support Vector Machine)来解决这种带有权重的分类问题。
在不同的数据集上验证了上文所提出算法的可行性。综合来看,该算法在一组全新的行为上进行测试的时候,通常可以达到50%~70%的精度,而对于过去传统的机器学习算法而言,由于完全没有训练数据,除了大规模标注全新的训练数据之外,在目标领域没有任何标注的情况下,已有的基于分类的算法是无法解决这个问题的。
与前面所描述的模型不同,如果动作识别模型在任何的目标领域内,没有任何的标注信息。但是,模型所用的传感器则属于比较精确,而覆盖范围较小的类型,如射频识别等。因此,根据OSD模型(如3所示),可以把这类工作归结于<识别目标=“动作行为”,数据类型=“无标注,密集”,传感器=“小范围,精确”>。这一问题的解决对于在家居环境下老人监护问题的解决提供了良好的基础。在这一环境下,通常并不能实现预料到所有数据可能的标注。例如,可能收集过在某个家庭的数据,但由于资源有限的原因,可能并没有所有数据的标注。另外,由于不同家庭的传感器系统有所不同,可能也无法获得充足的标注数据。在此情况下,这种基于迁移学习的解决方法就显得至关重要。
结语
随着传感器技术的发展,越来越多的传感器数据得以慢慢积累。通过对这些数据进行挖掘,可以获得很多信息,如用户的位置、行为等。这些信息使得人们能够更好地理解用户的喜好和需求,并由此催生了很多前景广阔的应用。文中介绍了现有的一些较为基础的应用,例如利用这些传感器信息对人在室内的位置进行定位,或是根据人的位置、行为等信息来推断出一些群体性的行为或者是兴趣倾向。
未来,可以预见,基于传感器数据的行为识别必将得到更为广泛的拓展、理解和应用。例如,对于老年人在家居环境中的行为监测,目前还没有很好的解决方案,因为无法期望老年人可以一直记得在身体的不同部位佩戴传感器。此外,虽然可以通过人的位置、行为等信息来预测出他的兴趣以及即将实施的动作和行为,但是如何才能将这一信息与商业广告的推送更紧密、更有效地联合起来?此外,随着现在互联网上商务活动的不断增加,如何将这些在物理世界中通过传感器获取以及挖掘到的用户信息应用到网络上,同样是一个非常值得研究的问题,例如,用户在物理世界和在网络世界中的兴趣等信息能否很好的利用迁移学习的思想进行匹配和迁移。
最后,我们提到了缺少有标记的训练数据对行为识别算法可能造成的影响,并讨论了一种解决这个问题的基本方法。读者可能已经发现文中所提到的解决标注缺乏问题的算法几乎是完全依赖网络上的文本信息,而没有考虑传感器数据之间可能的相似度。一个很直观的理解是,当传感器接收的数据在该数据空间上组成图像时,一个可以预见的事实是,同一种活动在不同传感器的数据表示形式上会展现出比较类似的信号变化趋势。未来将会考虑在这一方向作进一步的研究,以更好地解决标注缺乏问题。
参考文献:略。